
Back-of-a-napkin AI economics
Plus; decision intelligence, a primer on the coming recession, and ML for ancient games
AltDeep is a newsletter focused on microtrend-spotting in data and decision science, machine learning, and AI. It is authored by Robert Osazuwa Ness, a Ph.D. machine learning engineer at an AI startup and adjunct professor at Northeastern University.
Last week…
…these things that have snagged my attention, discussed below:
A Googler gives an introduction to “decision intelligence”
A discussion on how genes encode neural networks in the brain (as opposed to training them from experience)
Data visualization of AI companies from AngelList
A primer on how to deal with the coming recession that looks useful for data scientists
AI journalism touches on deep learning hype
Using ML to learn the lost rules of ancient games
I’ve also been thinking about the economics of AI in SaaS products…
Mulling over an economic model of AI-powered SaaS
I overheard a conversation on the Amtrak’s Acela express between two VC’s talking about AI startups. One of them said that he either sees startups teams with strong technical chops in terms of building AI, or teams with an amazing go-to-market experience, but is struggling to find teams with both.
It got me thinking about how to model the the economics of building AI-powered SaaS apps — a problem that I tackle daily in my job at Gamalon. From what I’ve read economists are asking the question of what are the cost benefits of good predictions (e.g., this Forbes article). In my view, this focus on prediction is too lacking of nuance to be useful. For example, Jian-Yang’s hot dog app in the show Silicon Valley had excellent predictive accuracy…

I suspect the problem it is better to frame the problem as cost benefits from automating workflows for making decisions under conditions of uncertainty. This aligns with the traditional model of building a SaaS app by starting with a consulting use case and automating it with software. It suggests that an AI can now automate things that ordinary software couldn’t do before the learning and representation of knowledge required for decision-making could be part of the stack.
I suspect the answer is to do with economies of scale. The more a data science workflow is automated, the less data scientist labor cost is required. It becomes repeatable and scalable, creating a great deal of value.
However, in typical manufacturing economies of scale, there is an inflection point when average cost-per-unit increases with the production volume.

My intuition as an ML engineer tells me that a similar inflection point occurs for automating a data science consulting use case with ML. For example, maybe the cost of prediction errors starts to mount, or the costs of machine learning technical debt outweigh the cost of having a human doing the work. I also suspect the shape of this entire curve depends on the use case. Which use cases yield more favorable curves? Can we categorize them in some way?
So this is what I’ve been mulling about this week. Please reach out with your opinion if this hits a nerve (@osazuwa).
Ear to the Ground
Curated posts aimed at spotting microtrends in data science, machine learning, and AI.
Googler Cassie Kozyrkov’s introduction to “decision intelligence”
My Medium feed has devolved into a depressing mix between articles like “How to use deep learning to generate pics of manga girls” and “How to get a job in data science without knowing any math.” I am constantly looking for articles contextualizing machine learning and data science within the decision-making systems we want to deploy them in. So I was excited when I saw an article on “decision intelligence” by Cassie Kozyrkov, a Googler and prolific blogger.

She hashes out some key concepts about decision-making and its relationship with data science and machine learning. She demonstrates how decision science goes beyond merely what you do with a machine learning prediction or a decision rule in statistics, to something that touches on management science, social science, economics, cognitive science, and other fields.
Advances in deep learning have biased the common understanding of machine learning to the problem of replicating sensory perception — recognizing faces, images, sounds, etc. These are tasks animals perform well. For example, eagles have excellent vision. However, when we talk in terms of the decisions we want these tools to support, it is immediately apparent that we are not interested in eagle decision-making.
Introduction to Decision Intelligence - Towards Data Science
Related:
I felt her article was lacking in discussion of causal inference and digital experimentation, to crucial ingredients to building a software platform decision-making. So I include links to two upcoming workshops and conferences on these subjects.
“Do the right thing”: machine learning and causal inference for improved decision making — Neurips 2019 workshop
Interesting discussion about neural network biomimicry
A critique of pure learning and what artificial neural networks can learn from animal brains is a recent Nature paper that argues that biological neural networks come pre-trained at birth, but since genes can’t directly encode that much information, there must be some sophisticated information compression mechanism. The article a philosophical exercise. It is readable and takes both a sobering on AI hype while still having a hopeful view of AI’s future.
Zador, Anthony M. "A critique of pure learning and what artificial neural networks can learn from animal brains." Nature Communications 10.1 (2019): 1-7.
Exploratory data analysis of AngelList AI companies
This analysis breaks down data on AI companies in AngelList’s database according to market, investment amount, and location.
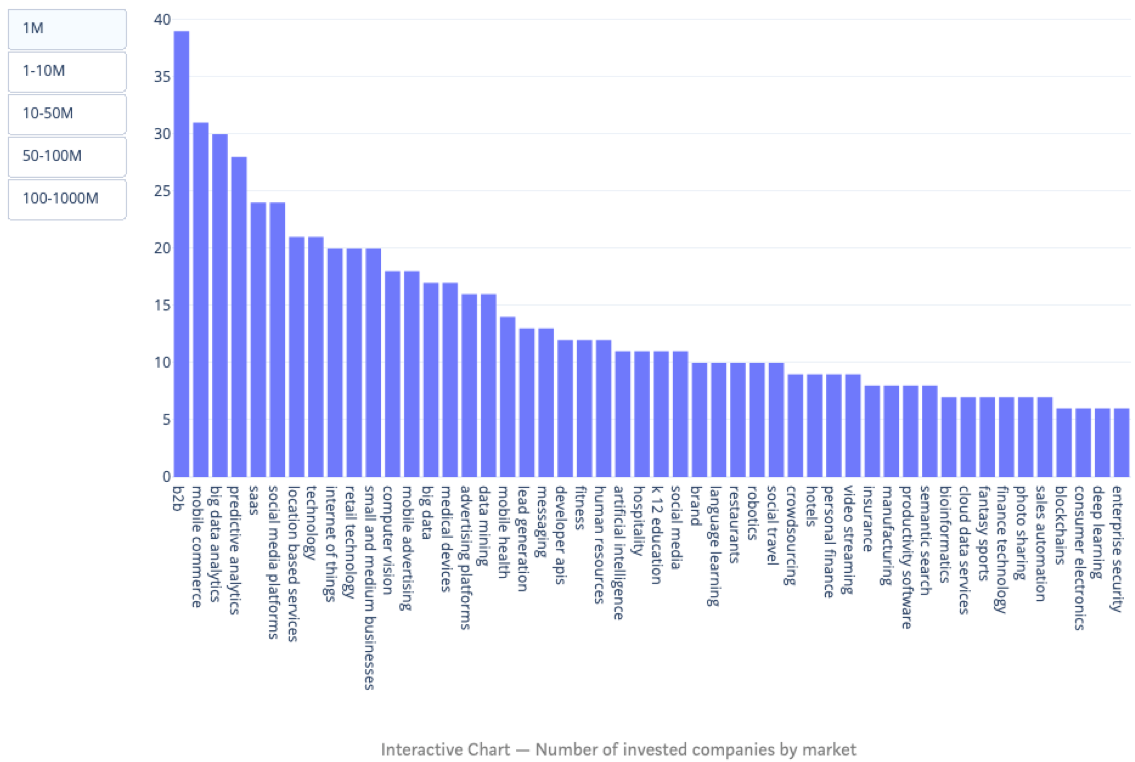
Data Analysis of 10,000 AI Startups — Towards Data Science
A useful recession primer with salient points for data scientists
A recession is coming. As someone whose career has endured two big ones, I want to prepare you, the person who hasn't lived through one yet, for what will come.
Some of the predictions here, based on the author’s experience, seem especially relevant to data scientist roles in pure AI play organizations.
Recession is coming — SysAdmin1138 Expounds
Axios on elite researchers’ concerns about how deep learning hype threatens the next breakthrough
Axios wrote a short piece summarizing concerns from top researchers in the field about how too much focus on deep learning is sucking oxygen away from other avenues of research that may lead to the next breakthrough. If you are plugged into debates about the direction of the field, you will have heard these voices and their opinions before (Gary Marcus’s deep learning skepticism, Pedro Domingos on research factions).
They also quote Yoshua Bengio, co-winner of the Turing Award for his work on deep learning, on how the next generation of researchers ought not to take their ideas as gospel. He’s right about that — I’ve interviewed many people who believe deep learning can solve any problem with enough data and the right architecture. Yet, I snapped this picture of Bengio on this panel on causal inference at Neurips last year (third from right)…

He’s aware that causal reasoning is something deep learning in its raw form can’t do (a mathematically provable statement) and is already working on the problem.
Anyhow, reporting on this debate by AI journalists, particularly those working for a publication as influential among investors and policy elites as Axios, is new.
A reality check for AI hubris — Axios
Related:
This recent profile on Geoffrey Hinton, who won the Turing Award for deep learning along with Bengio and Yann LeCunn, is a useful reminder how these guys worked for decades on what was considered fringe research, until it wasn’t. And of course, there is Thomas Kuhn’s work
Mr. Robot; The AI superstars at Google, Facebook, and Apple — They all studied under this guy — Toronto Life
Kuhn, Thomas S. "The structure of scientific revolutions." Chicago and London (1962).
AI Long Tail
Pre-hype AI microtrends.
The Digital Ludeme project applies ML to ancient games

The “Digital Ludeme Project” is a study the history of human games. It purportedly uses machine learning to reconstruct lost knowledge about these games. The machine learning is based on a class grammar for games (kind of like a context-free grammar in linguistics and natural language processing). Based on this grammar, it tries to infer the rules of the game from available data.
Digital Ludeme Project — Modelling the Evolution of Traditional Games
Browne, Cameron. "Modern techniques for ancient games." 2018 IEEE Conference on Computational Intelligence and Games (CIG). IEEE, 2018.
Thanks again for reading. I’m trying to double the subscriptions this month. With enough subscribers, I can write more in-depth and well-researched posts and reports. So please subscribe or forward to folks who would find this content interesting.
~ Robert